高等教育領域數字化綜合服務平臺





中國科學技術大學
中國科學院
- 19 高校采購信息
- 221 科技成果項目
- 0 創新創業項目
- 0 高校項目需求
時空面板數據模型的研究
2021-04-10 00:00:00
云上高博會
http://www.g2h0uzv.xyz
關鍵詞:
時空面板


所屬領域:
項目成果/簡介:
近日,中國科學技術大學管理學院在時空面板數據模型的研究中取得重要進展,突破經典的廣義極大似然估計和廣義矩估計理論框架,提出了基于空間權重矩陣特征分解的估計和模型選擇方法。相關論文在學術期刊《美國科學院院報》上發表。
現在很多大數據(環境,疫情,犯罪,物流,區域經濟等)呈現出時間和空間的復雜相依關系,由于時空的交互影響提高了對應的時空模型的估計難度。有別于已有的復雜估計方法,文章改變傳統的估計思路,充分利用時空數據的空間結構特征,采用空間權重矩陣的特征分解,極大的簡化了估計方法,提高了估計精度和運算速度,并提出了相應的模型選擇方法。理論部分模型的示意圖如下圖所示:

文章以 2008 年 1 月到 2013 年 12 月(72 個月) 138 個美國匹茲堡行政地區的犯罪數據為例做了示范。在這個例子中,犯罪數據重罪(Part I)和輕罪(Par II)在138個行政區的平均犯罪個數分布如下圖:
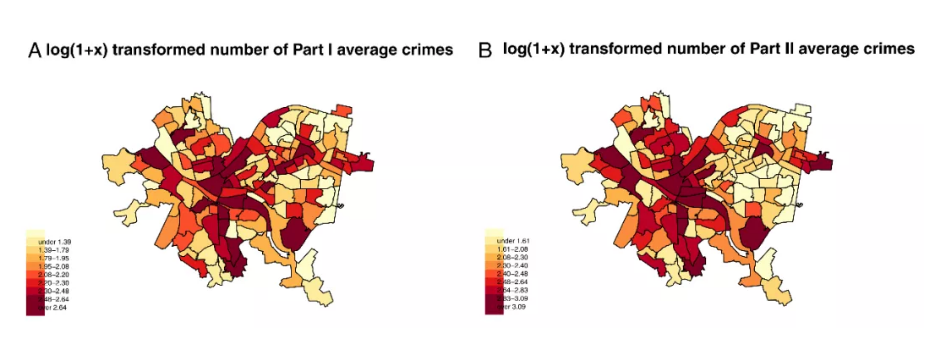
文章還選取了 15 個區域社會經濟變量作為解釋變量,包括區域總人口、收入、失業率、貧苦率、非裔比例、教育水平等。模型的擬合程度指標R平方(接近1時,擬合程度高)達到 0.98,表明選擇的模型非常好的擬合了數據。數據分析結果可以用于以輕罪發生率預測重罪發生率,解釋犯罪學的“破窗理論”,分析重罪發生率和總人口、收入和貧困等的量化關系。
論文鏈接:
https://doi.org/10.1073/pnas.1917411117
詳細閱讀:
http://news.ustc.edu.cn/2020/0318/c15884a414854/page.htm
項目階段:

掃碼關注,查看更多科技成果
取消
確定