




- 15 高校采購信息
- 634 科技成果項目
- 4 創新創業項目
- 0 高校項目需求
面向垂直應用的高質量檢索增強生成大模型服務


大語言模型(Large Language Model, LLM)是一種新興的人工智能技術,也是人工智域的革命性成果。當前,大語言模型已被應用在文本理解與生成、知識問答、聊天娛樂等各種工作場景,對日常工作生活方式產生了極大的影響。傳統的LLM雖然具備強大的文本生成能力,但由于其訓練數據是固定的,隨著時間推移可能會變得過時,且缺乏提供準確、上下文響應的能力,對一些需要特定領域知識的垂直應用場景的支撐能力不足。檢索增強生成(Retrieval-Augmented Generation,RAG)是一種結合了LLM和信息檢索技術的人工智能技術,通過構建知識檢索與問答增強智能體(Agent),利用外掛知識庫來增強生成模型的能力,可有效解決生成模型由于訓練知識缺乏或過時所帶來的局限性,大幅度提升大模型的問答質量,同時有效抑制模型幻覺,保護私有知識產權,在對專業或領域知識需求較高或對信息新鮮程度要求較高的垂直LLM服務系統中的作用尤為突出。
目前,RAG的知識檢索過程主要通過使用內容分片和相似度匹配等機制來檢索與Query有關的文本片段,該方式雖然可調節知識匹配的范圍,但非常容易造成概念混淆、引入無關數據噪聲等問題,且難以設置合適的閾值:在相似度閾值要求較低時,所匹配的數據量雖然可能較多,但與答案相關的信息密度很低,造成大量無關信息的污染;閾值較高時則匹配到的知識片段較少,降低回答結果的知識點覆蓋面和準確性。此外,由于匹配機制要求對知識庫進行分片匹配,會造成匹配結果的信息割裂,導致檢索結果完整性很差,對表格等類型的數據的檢索能力也較弱。上述問題導致目前主流的基于向量化知識庫的垂直RAG服務存框架在知識檢索信息密度低、知識碎片化、存在大量無關信息干擾、知識覆蓋面窄等問題,對垂直RAG服務的性能造成了非常大的影響,降低用戶體驗質量。
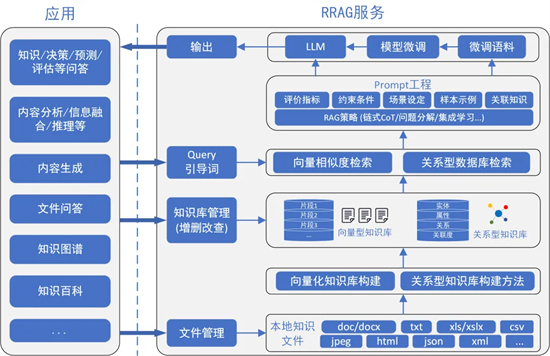
圖1 RRAG服務框架
針對上述問題,我校科研團隊研發了關系型檢索增強生成(Relational RAG,RRAG)框架以實現面向面向垂直應用的大模型服務。RRAG服務框架如圖1所示,其核心工作和優勢包括以下三個方面:
(1)高質量關系型知識庫構建。當前RAG知識庫的構建一般采用向量化的方式將語料信息轉換為分片段的向量庫,為后續知識匹配或查找過程提供支撐。該方式雖然簡單,但其未對知識數據進行任何的精煉、提取等過程,對表格等數據的支撐能力很弱,在后續知識匹配查詢時效率也較低。為此,RRAG創新性地使用關系型知識庫來實現知識檢索增強過程,通過將知識文件轉換為關系型知識庫,從深度、廣度、粒度、關聯度上提升知識檢索結果的質量,為提升RAG智能體服務能力高效、精準的知識檢索能力提供根本支撐;
(2)規范、應用面廣的RRAG Prompt構造方法。提示詞工程(Prompt engineering)是引導大模型給出符合業務需求結果的重要一環。目前,Prompt工程尚未形成統一的規范或模式,而如何設計面向RAG的Prompt設計規范仍是一個開放課題。RRAG構建了一套規范、普適的Prompt設計方法和Prompt生成機制,為最大可能激發LLM的潛力、提升模型輸出結果的質量提供Prompt方法支撐;
(3)基于RRAG的大模型低成本微調方法。大模型微調對硬件算力和語料質量的要求較高。在具備充足算力條件的情況下,如何獲取高質量RAG訓練語料是實現RAG大模型微調的關鍵。采用人工標注的方式不僅效率低下,成本也非常高,同時語料的多樣性也較為欠缺。為此,RRAG可實現針對LLM低成本微調方法,在構建關系型知識庫的基礎上,可進一步實現RAG訓練語料的自動高效生成,無需人力成本,生成語料多樣,實現面向RAG服務的大模型的低成本微調過程,進一步增強RRAG的服務質量。
RRAG可支撐豐富的上層應用,包括面向各種需求的內容生成,如知識問答、評估、預測、知識融合、多模態決策等;支持知識圖譜應用,可實現關系查詢和推理等功能;支持將原始語料內容凝練總結為規范化的知識百科信息。
小試階段/試用階段。
RRAG已應用于智慧農業和航空航天相關項目2項,已完成RRAG系統的第一版本的搭建,具備知識問答、評估問答、知識圖譜、知識百科、文件問答、模型微調等功能,具備可演示平臺。在知識問答場景下,相比于通用的向量型RAG框架,對知識點的覆蓋全面性和回答準確性可提升10%以上,甚至更高。
大模型具有非常強大的內容生成、信息融合、邏輯推理、少樣本學習等能力,應用得當可有效提升知識獲取的智能性和可靠性,并輔助完成知識獲取、智能辦公、輔助決策、評估診斷、趨勢預測等多樣化應用。RRAG核心優勢在于可有效增強知識檢索結果的質量和范圍,進而有效提升RAG生成能力,可在上述應用中發揮重要作用。

掃碼關注,查看更多科技成果